


7.3.1 모델의 동작방식
•
모델 가정
◦
Hidden Markov Model(HMM)은 직접적으로 관측이 불가능한 상태를 가진 시스템을 상정
◦
미래 사건의 확률이 시스템의 현재 상태만으로도 충분히 계산될 수 있음
•
Markov과정
◦
두 상태 모두 다른 시간 단계에서 통계적으로 다른 상태로 바
뀌는 것보다는 현 상태를 유지할 가능성이 높다고 가정
◦
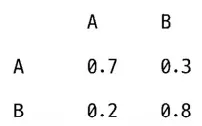
현재 시스템 상태 A,(1 , 0)일때(상태 B는(0 , 1)). 이때 시스템이 상
태 A를 유지할 확률은 0 . 7이며,상태 B로 바뀔 확률은 0 . 3
•
은닉 마르코프 모형(hidden Markov model)
◦
관측으로부터 시스템의 상태를 직접적으로 추론할 수 없고, 관측은 시스템의 상태에 대한 단
서를 제공(그림 7-4)
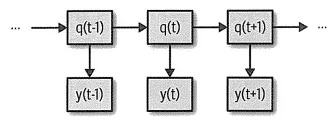
그림 7-4 HMM에 대한 과정으로 특정 시간에서 시스템의 실제 상태를 x(t)로 표현합니다. 또 특정 시간에서 관측 가능한 데이터는y(t)로 표현합니다. y(t) 입장에서는 오로지 x(t)만 고려. 즉 x(t)를 이미 알고 있다면 x{t-1)은 y(t) 예측에 추가 정보를 제공하지 않는 것입니다. 마찬가지로 y(t十1)의 예측에는 x(t)의 영향만 있을 뿐,x(t~ 1)로 부터는 어떠한 추가 정보도 없습니다. 이것이 바로 마르코프가 바라보는 시스템입니다.
•
HMM의 실제 사용 사례
◦
금융시장의 체제 전환식별
◦
DNA 염기순서 정보의 분류,예측,복원
◦
ECG 데이터에 반영된 수면 단계의 인식
7.3.2 모델을 적합 시키는 방법
•
시스템 구성 가정
◦
x(t)에서 x(t+1)로 전환될 확률. 행렬로 표시, 크기는 상태의 개수에 따라 다름
◦
x(t)가 주어졌을 때 관측y(t)가 나타날 확률 emission probability
◦
시스템의 초기 상태
•
모델 적합화 단계
◦
가능한 각 은닉상태에 대한 개별 방출 확률과 각 은닉상태 간의 전환 확률을 추정.(바움-웰치 알고리듬)
◦
전체 관측에서 각 시간 단계별 가장 가능성이 높은 은닉 상돼를 식별. (비터비 알고리즘)

•
바움-웰치 알고리듬(Baum-Welch Algorithm)
◦
우도 함수(Likelihood Function)의 정의
▪
우도 함수는 주로 매개변수 추정, 특히 최대우도추정법(Maximum Likelihood Estimation, MLE)에서 사용. 이 함수는 관찰된 데이터가 주어졌을 때, 가능한 매개변수 값들의 우도를 나타내며, 이를 통해 가장 데이터를 잘 설명하는 매개변수 값을 찾음.
◦
우도 함수의 적용
▪
두 개의 분포를 상정하는 무작위 사건 및 각 시간 단계에서 특정 상태일 확률을 결정(예: 시간 단계 에서 상태 A나 B가 될 확률)
▪
각 시간 단계에 추정 상태를 할당하면,그 추정 상태로 방출 확률을 재추정
▪
과정을 반복하여 궤적의 추적 향상 을 위해 새롭게 갱신된 방출 확률변수를 사용하여
미분, 수치적 최적화 기법 등을 사용하여 최대우도 추정값 도출
◦
비터비 알고리즘
▪
HMM 과정의 파라미터가 관측 가능한 측정값으로 구성된 시계열을 구성하게 하는 가장 가능성 높은 상태들의 계열 추정
▪
동적 프로그래밍 알고리즘. 즉 특정 해결책에 도달하기 위해 부분적인 해결책을 만들고 저장하여,적합 범위를 완전하면서도 효율적으로 탐색.
동적 프로그래밍
7.3.3 코드로 보는 HMM의 적합 과정
•
depmixS4 패키지로 작업.
◦
코드를 시용해 적절한 시계열을 만듬


◦
상기 코드는 매수세, 약세, 중립, 패닉이라는 네 가지 모드의 주식시장에서 영감을 받은 예제. 각 상태의 방출 확률 분포를 설명하는 변수(특정 상태에서 측정된 기대 값을 나타내는 mu 및 -Sd 변수)와 같이 상태가 지속될 일수는 무작위로 선택
◦
샘플이 포괄하는 날 중 몇 일이 상태 추적에 시용하는 변수인 true.mean에 해당하는지 확인해 생성된 시계열의 모양과 각 상태의 빈도를 파악

◦
모델은 두 단계로 적합
▪
우선 예상 분포, 상태 개수, 적합에 사우될 입력 데이터 등이 depmix() 함수로 지정. 다음 fit 함수를 통해 모델이 적합. 이때 fit 함수에는 모델 사용에 대한 내용이 전달.
▪
마지막으로 posterior() 함수를 사우하여 적합된 모델로부터 상태 레이블에 대한 사후분포를 생성.

▪
상기 코드에서는 관측데이터로 returns 벡터를 제공하여 hmm.model을 생성. 상태의 개수(4)를 지정, family 파라미터를 통해 방출 확률이 가우스 분포를 따른다는 것 을 지정. 그다음 fit() 함수로 모델을 적합, posterior() 함수로 사후 획률을 계산. 사후 획률은 적합 과정에서 결정된 모델의 피라미터에로 특정 시간에서의 특정 상태에 대한 확률을 제공.
•
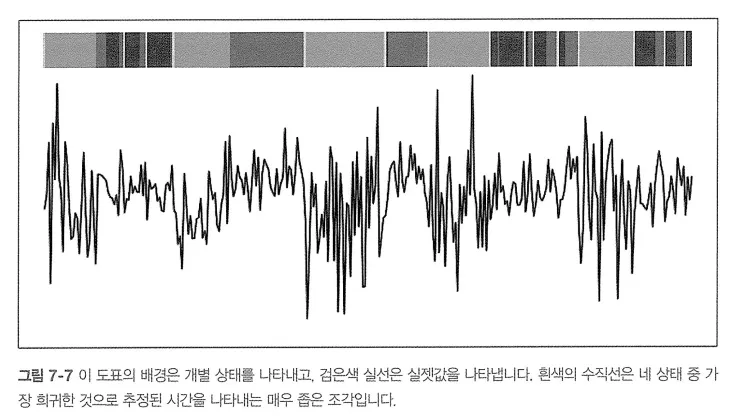
다음과 같이 측정된 값으로 상태를 시각화

•
HMM은 다양한 종류의 데이터를 분석하는 데 적합. 현재 금융시장이 성장기인지, 불황 기인지를 모델링하고 세포 내의 단백질 폴딩이 어느 단계에 있는지 결정하며 (딥러닝이 도래 하기 전) 사람의 움직임을 설명하는 데 시용. 이러한 모델은 예측하기 보다 시스템의 역동성을 이해하는 데 더 지주 우통하게 사용됩니다.
•
HMM을 시용할 때 다음과 같은 몇 가지 추론 작업에 직면.
◦
괸측의 계열을 생성하는 상태들의 가장 가능성 있는 설명을 결정
◦
관측의 계열, 상태에 대한 설명, 각 상태의 방출과 전환 획률을 통해 가장 기능성이 높은 상태의 연속적인 순서를 결정.
◦
필터링과 평활화입니다. 필터링은 가장 최근의 관측이 주어졌을 때 가장 최근의 시간 단 계에서의 은닉 상태를 추정. 평활회는 특정 시간 단계의 이전, 현재, 이후에 대한 관측을 토대로 해당 시간 단계의 은닉 상태에 대한 가장 가능성 있 는 분포를 결정.
