

.png&blockId=04a8d577-ace8-4bac-bec8-3da8a3f63bbd)
@3/3/2023
시계열 사이에 유사한 정도를 측정하는 개념으로서 다양한 시계열 분석 및 응용(e.g., 군집화, 분류, 검색)에 활용된다.
시계열 유사도 측정 방법
1. 유클리드 거리 (Euclidean Distance)
두 시계열 사이의 유사도를 측정하는 가장 기본적인 방법으로 같은 타임 스탭에 해당되는 벡터인 두 데이터 포인트 의 차이를 기반으로 측정된다.
제약 조건으로 는 같은 길이를 가져야 하며, 측정된 거리 는 의 범위를 가진다. 유클리드 거리를 통해 측정된 유사도는 시계열의 값 차이 뿐만 아니라 길이에 영향을 받기 때문에 길이가 서로 다른 시계열 쌍들의 유사도를 비교할 수 없다.
•
예:
2. MAPE (Mean Absolute Percentage Error)
MAPE는 회귀 모형의 손실 함수로 널리 적용되고 있으며, 시계열 유사도 측정에도 적용 가능하다. MAE(Mean Absolute Error), RMSE(Root Mean Square Error) 등의 회귀 관련 평가 지표들도 마찬가지로 유사도 측정에 적용할 수 있다.
유클리드 거리와 마찬가지로 두 시계열 가 같은 길이를 가져야 하며, MAPE 측정 값은 비대칭적이다(asymmetric). 이는 기준 시계열( 또는 )을 무엇으로 정하는지에 따라 MAPE 값이 달라진다.
3. 피어슨 상관계수 (Pearson Correlation Coefficient)
공분산을 범위로 표준화하여 측정되는 상관계수이며, 에 가까울수록 두 시계열이 유사하다고 해석한다.
4. Dynamic Time Warping (동적 시간 워핑)
두 시계열 사이의 의존성 또는 상호작용이 존재하는 경우, 같은 타임 스탭에서 두 시계열의 데이터 포인트가 대응되지 않고, 약간의 시간 차(lag)를 두고 대응되는 형태로 나타나는 경우가 많다. 이런 경우, 유클리드 거리와 같이 동일한 타임 스탭의 데이터 포인트 사이의 차이를 기반으로 하는 방법으로 유사도를 측정하는 것은 적합하지 않다.
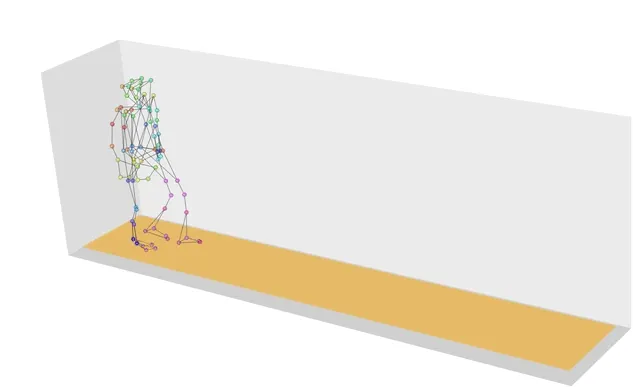
사람의 걸음 패턴은 대체로 비슷하지만 보폭과 속도에서 약간의 차이가 발생한다. 이런 경우의 시계열 신호의 유사도(예: 유클리드 거리)를 측정하면 어떤 결과가 나오게 될까?(티스토리)
DTW는 두 시계열의 패턴을 비교하여 Lag이 존재하지만 동일한 패턴 지점의 두 포인트를 대응시키는 방법이다.
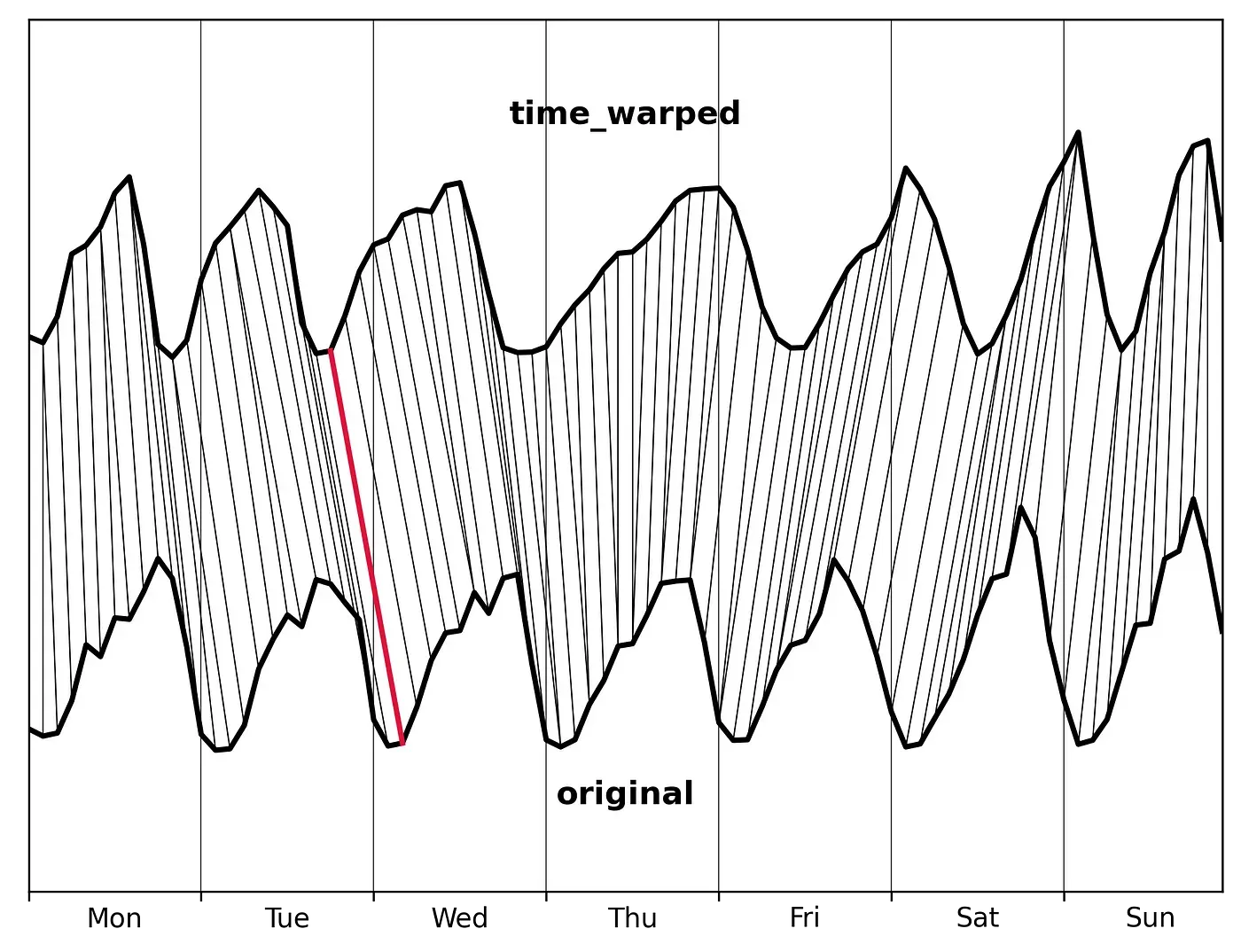
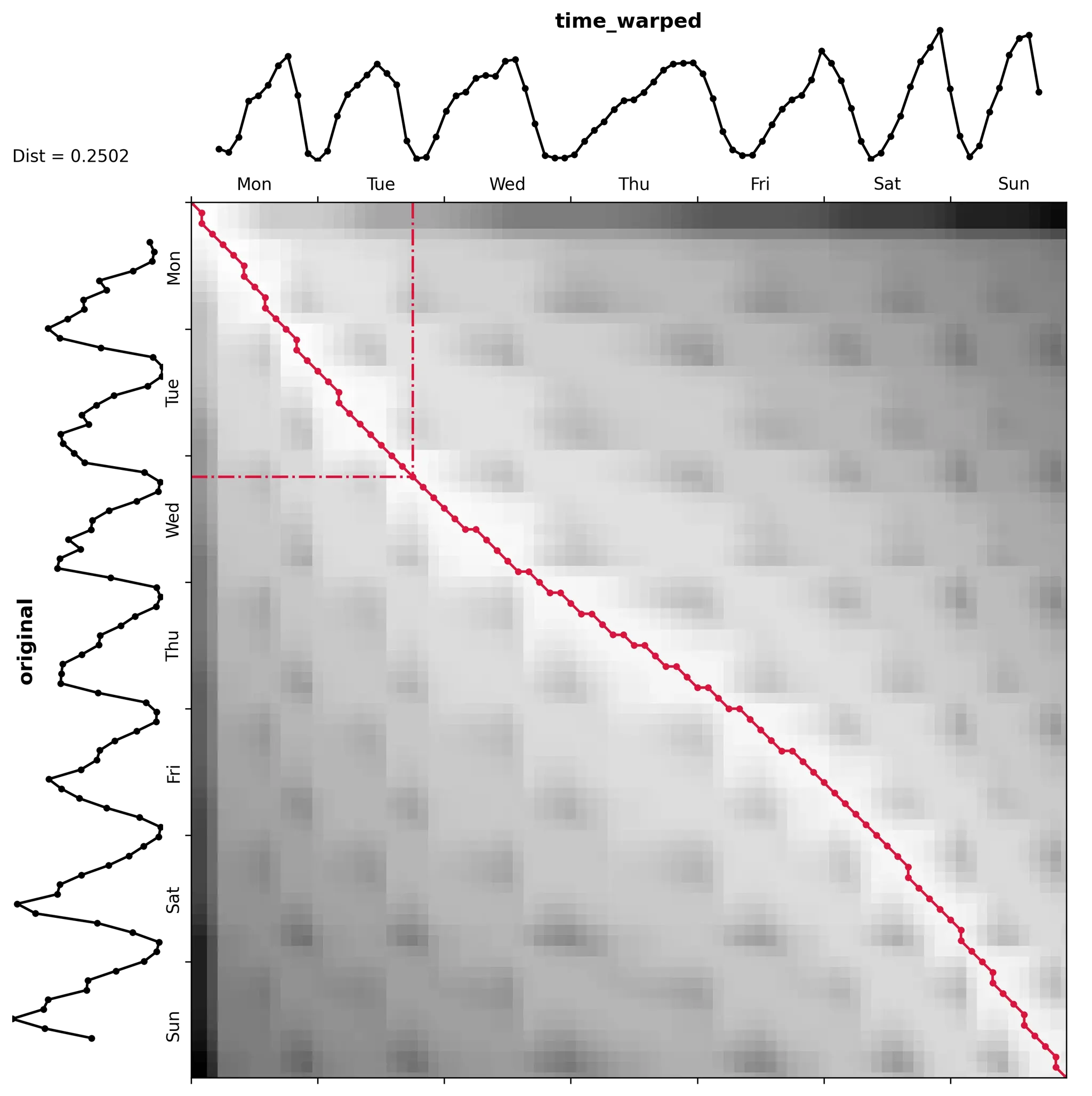
데이터 포인트 매핑은 유글리드 거리를 기반으로 가능한 데이터 포인트 쌍의 비용(와핑 경로 비용)들을 계산하고 비용의 총합을 최소화하는 최적화 과정에 의해 수행된다. DTW는 또한 길이가 서로 다른 시계열에도 적용할 수가 있다.
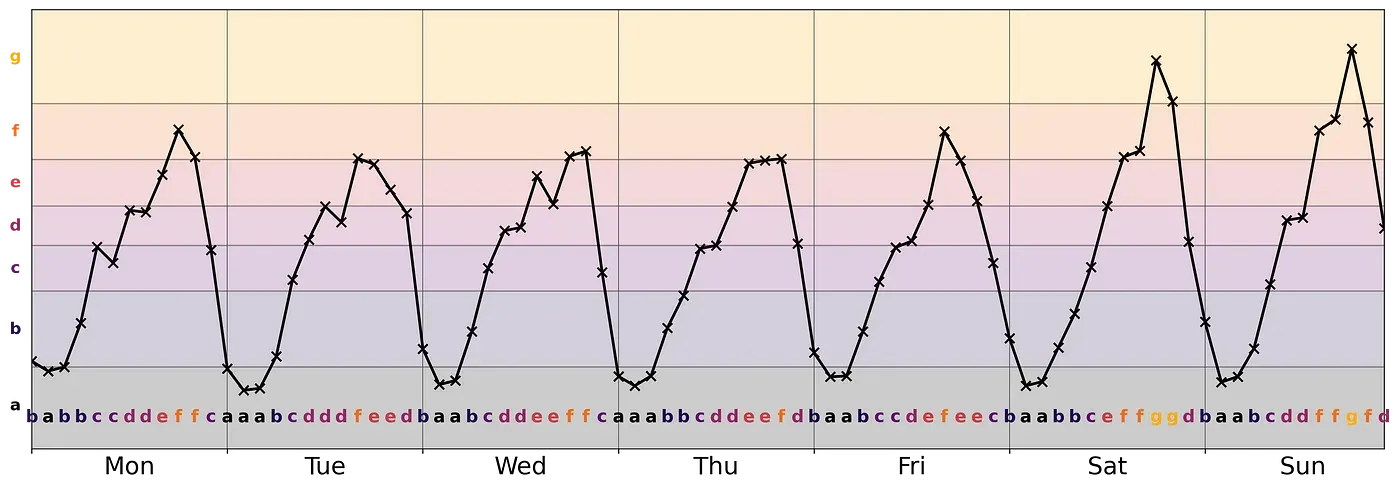
5. Compression-Based Dissimilarity (CBD)
CBD의 접근법은 원본 시계열에 압축 기법을 적용하여 계산 효율적으로 유사도를 측정하는 것이다. 예를 들면, SAX(Symbolic Aggregate approXimation)과 같이 시계열 값을 구간화하여 연속형 수치에서 범주형 값으로 이루어진 시퀀스로 인코딩한 다음, 시퀀스 사이의 유사도를 측정할 수 있다.
유사도 측정 방법 비교
시계열 유사도 측정 방법을 비교하기 위해 다음과 같이 원본 시계열(original)을 변형시켜 총 5개의 비교 시계열들을 생성한다.
•
time_offset: 원본 시계열에 일정 시간 차(lag)를 적용
•
value_offset: 원본 시계열에 일정 값 차이를 적용
•
scaled: 원본 시계열의 스케일을 변형
•
noise: 원본 시계열에 노이즈를 적용
•
time_warped: 원본 시계열에 warp(뒤틀림) 효과를 적용
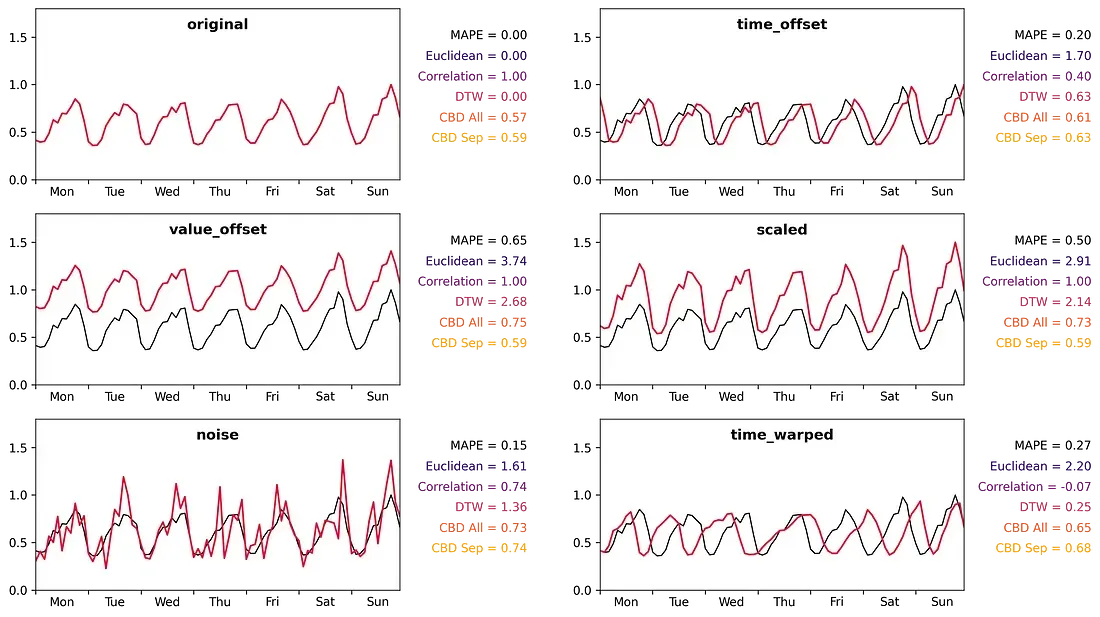
시계열 유사도 측정 결과: time_offset과 time_warped 케이스의 경우 DTW가 가장 유사도를 잘 포착하는 것으로 분석되며, value_offset과 scaled 케이스의 경우 피어슨 상관계수가 가장 효과적인 방법인 것을 알 수 있다. 마지막으로 noise 케이스의 경우 MAPE 또는 CBD가 추천된다. CBD의 경우 value_offset, scaled, noise 케이스에서 대체적으로 유사도를 잘 측정하는 것으로 분석된다(Medium).
참고 문헌
•
•
•
•
구본용, “시계열 데이터 마이닝”, 전산구조공학, 2018.
