

.png&blockId=04a8d577-ace8-4bac-bec8-3da8a3f63bbd)
, 2022년 09월 12일
Covariance (공분산)
: 두 개의 확률 변수의 선형 관계를 나타내는 값
•
변수 여럿으로 구한 분산 → 공이 ‘함께’라는 의미
수식
두 변수 X, Y에 대해

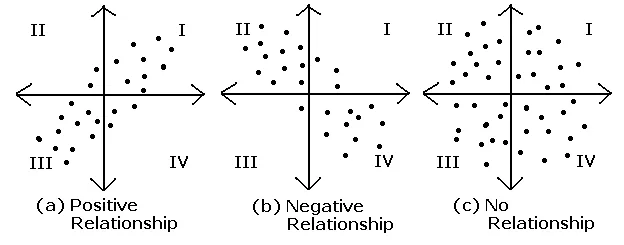
Cov(X, Y) > 0 X가 증가 할 때 Y도 증가 → 양의 선형(linear)관계
Cov(X, Y) < 0 X가 증가 할 때 Y는 감소 → 음의 선형(linear)관계
Cov(X, Y) = 0 두 변수 간에 선형 관계가 없으며 두 변수는 독립 (단, 역은 성립 X)
Correlation Coefficient (상관 계수)
: 두 변수 간의 관계로, 하나의 변수가 변화함에 따라 다른 변수가 변화하는 정도
•
두 변수 X, Y 간의 Covariance(공분산)을 표준 편차로 나눠 값의 범위를 -1 ~ 1로 나타낸 것
(just 공분산을 표준화한 것)
상관 계수의 종류
1.
Pearson (피어슨 상관 계수) → General
: 공분산을 표준화 하여 이용하는 상관 계수(공분산을 -1~1의 범위로 바꾼 것 뿐)
•
연속형 변수의 상관 관계 측정 (ex. 키, 몸무게)
•
parametric test (모수 검정)
2.
Kendall Tau Rank (켄달 상관 계수)
: 변수값 대신 순위로 바꿔 이용하는 상관 계수
•
서열 척도 사용한 변수 포함되거나 두 변수가 비선형적 관계일 때 사용
•
샘플 사이즈가 적거나, 데이터의 동률이 많을 때 유용
•
non-parametric test (비모수 검정)
3.
Spearman (스피어만 상관 계수)
: 변수값 대신 순위로 바꿔 이용하는 상관 계수
•
서열 척도 사용한 변수 포함되거나 두 변수가 비선형적 관계일 때 사용
•
데이터 내 편차와 에러에 민감하고 일반적으로 켄달 상관 계수보다 높은 값을 가짐
•
Non-parametric test (비모수 검정)
4.
Time Lagged Cross Correlation (TLCC)
5.
Dynamic Time Warping (DTW)
피어슨 상관 계수는 선형 상관 관계지만 켄달과 스피어만은 상관 관계에 대한 값이기 때문에 피어슨처럼 선형 관계 가질 필요 없이 두 변수에 증감만 존재하면 됨
Time-Lagged Cross-Correlation
: Time-series를 Shifting하며 데이터 전 범위에 대해 Pearson 상관 계수를 계산하여 나타냄.
•
데이터의 식별 가능(leader-follower relationship)
•
두 데이터 사이의 인과관계 파악 가능(leader-follower relationship)

References
•
•
•
•
•
•
•
•
•
•
•
•
