


K-최근접 이웃 예측 방법
1. 이론적 배경
•
K-NN은 가장 간단하고 효과적인 머신러닝 알고리즘 중 하나로, 분류(Classification)와 회귀(Regression) 작업 모두에 사용.
•
이 알고리즘은 간단함과 효과성 덕분에 다양한 응용 분야에서 많이 사용되며, 대표적인 응용 사례로는 추천 시스템, 이미지 인식, 패턴 분류 등이 있음.
출처: towardsdatascience
•
새로운 데이터를 예측할 때, 데이터 간의 거리를 계산하여 기존 데이터 중에서 새로운 데이터와 가장 가까운 K개의 데이터를 선택.
•
분류 문제에서는 K개의 데이터 중에서 가장 많이 등장하는 클래스를 예측 결과로 선택.
•
회귀 문제에서는 K개의 데이터의 평균값 또는 가중 평균값을 예측값으로 계산.
•
K의 값이 너무 작으면 과적합(overfitting)이 발생할 수 있고, 너무 크면 과소적합(underfitting)이 발생할 수 있으므로, 적절한 K 값을 선택하는 것이 중요.
•
거리 측정 방법으로는 주로 유클리드 거리(Euclidean Distance), 맨해튼 거리(Manhattan Distance), 코사인 유사도(Cosine Similarity) 등이 사용.
•
K-NN은 모델을 학습할 때 별도의 훈련 과정이 없고, 예측 시점에서 모든 데이터를 참조하여 계산하기 때문에, 데이터가 많아질수록 계산 비용이 커질 수 있다는 단점이 있음.
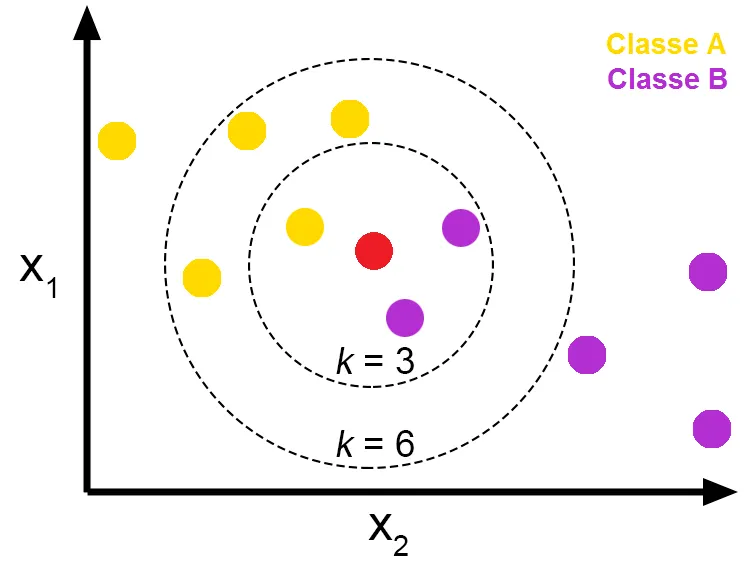
2. 동작 원리
2.1 거리 측정 방법
(1) 유클리드 거리 (Euclidean Distance)
•
점과 점 사이의 거리를 구하는 방법
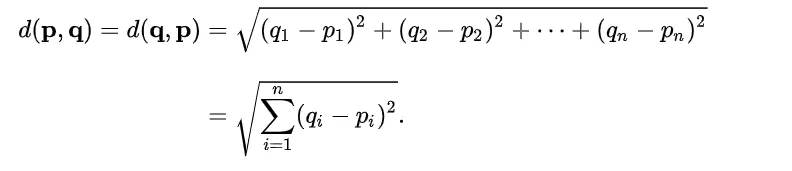
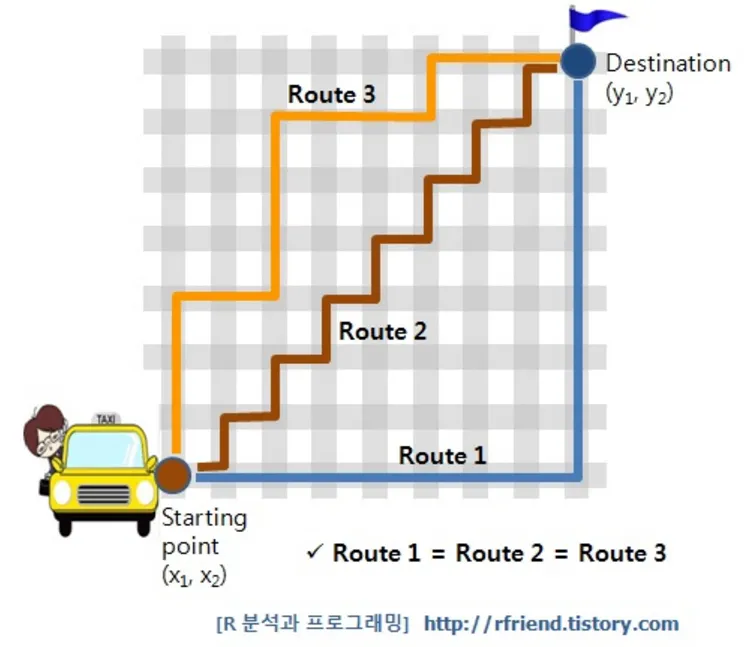
(2) 맨해튼 거리 (Manhattan Distance)
•
두 점 사이의 수직 및 수평 거리의 합을 구하는 방식으로, 격자 형태의 경로에서 이동할 때의 거리를 구하는 방법
코사인 유사도 (cosine similarity)
•
두 벡터 간의 각도를 측정하여 유사성을 계산하는 방법으로, 값이 1에 가까울수록 두 벡터의 방향이 유사하다는 것을 의미
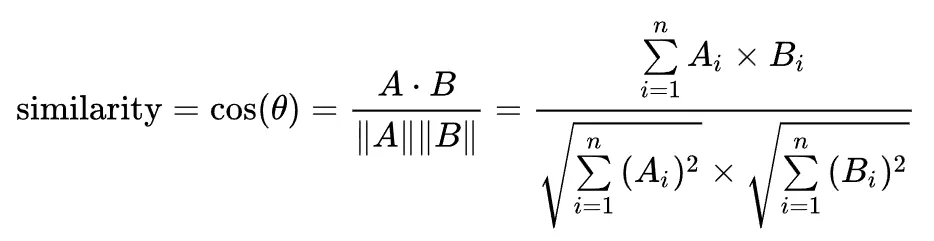
출처 : wikipedia
[코드 구현 및 데모 1]
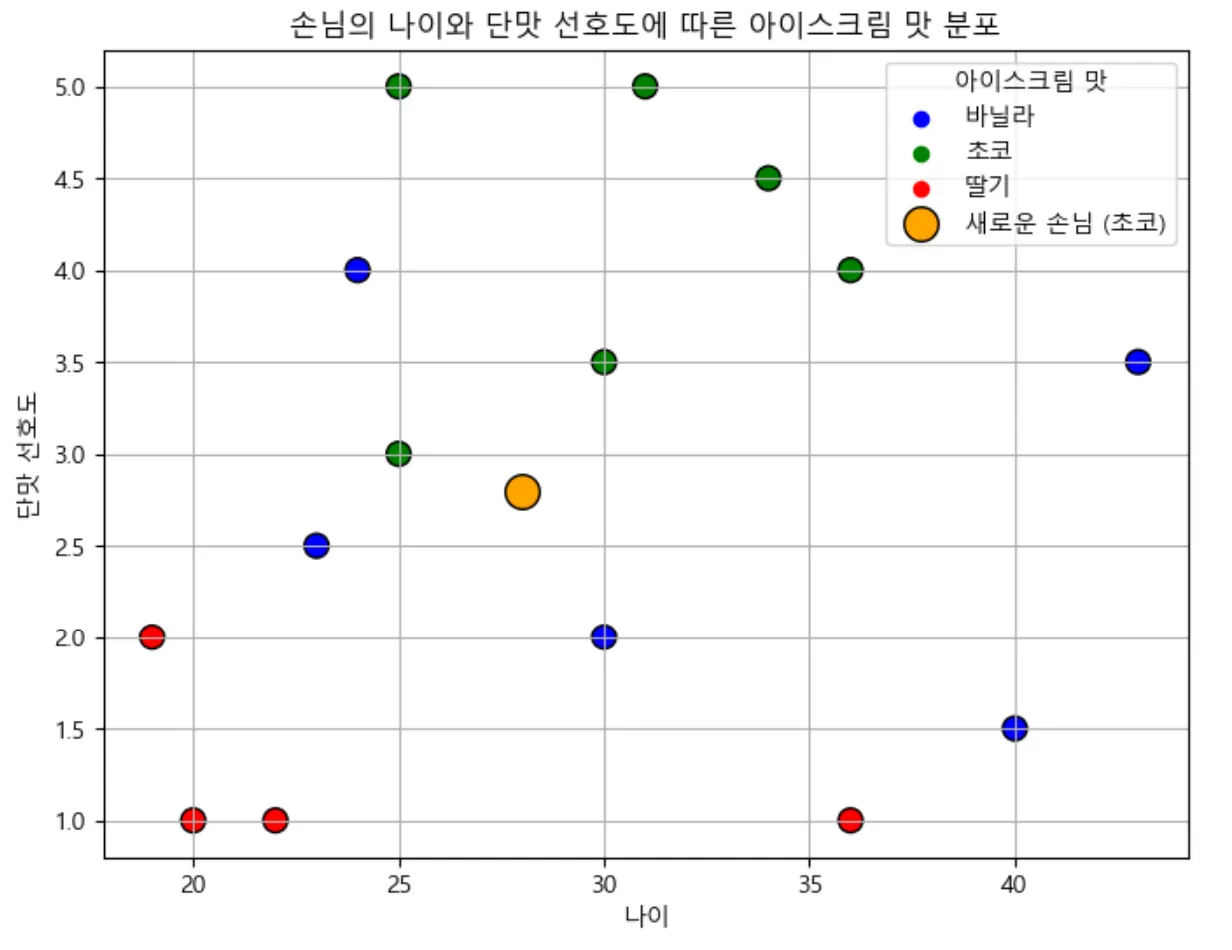
아이스크림 가게에서 새로운 손님이 들어왔을 때, 손님의 나이와 단맛에 대한 선호도를 바탕으로, 손님이 가장 좋아할 만한 아이스크림 맛을 추천해주는 장면. K-NN 알고리즘을 이용해 손님의 데이터를 기존 손님들과 비교하여 바닐라, 초코, 딸기 중 가장 적합한 맛을 예측. (당도 : 초코 > 바닐라 > 딸기)
import numpy as np
from sklearn.neighbors import KNeighborsClassifier
# 1. 데이터 설정: [나이, 선호하는 단맛 정도]
# 예시 데이터: 나이, 단맛 선호도(1~5 점수)
X = np.array([[25, 5], [30, 3.5], [30, 2], [24, 4], [25, 3],
[19, 2], [40, 1.5], [34, 4.5], [31, 5], [22, 1],
[43, 4], [36, 1.0], [23, 2.5], [36, 4], [20, 1]])
# 아이스크림 맛 레이블 (0=바닐라, 1=초코, 2=딸기)
y = np.array([1, 1, 0, 0, 1, 2, 0, 1, 1, 2, 0, 2, 0, 1, 2])
# 2. K-NN 모델 생성 및 실행
knn = KNeighborsClassifier(n_neighbors=3)
knn.fit(X, y)
# 3. 새로운 손님 데이터 예측 (나이 28, 단맛 선호도 2.5)
new_customer = np.array([[28, 2.5]])
predicted_flavor = knn.predict(new_customer)
flavors = ['바닐라', '초코', '딸기']
print(f"추천 아이스크림 맛: {flavors[predicted_flavor[0]]}")
Python
복사
추천 아이스크림 맛: 초코
산점도 그리기 코드
•
최근접 이웃의 개수에 따라 결과가 각각 달라질 수 있다. 이 문제를 해결하는 한 가지 방법은 검증점과 k개의 최근접 이웃 각각의 거리를 고려하여 분류에 가중치를 주는 것
2.2 KNN 가중치 예측 방법
유사도가 구해지면 평점을 예측하고자 하는 사용자(또는 상품)와 유사도가 큰 k개의 사용자(또는 상품) 벡터를 사용하여 가중 평균을 구해서 가중치를 예측.
(1) KNNBasic
• 평점들을 단순히 가중 평균.
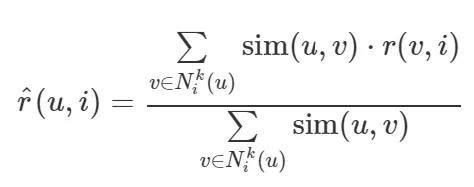
출처 : datascienceschool
(2) KNNWithMeans
• 평점들을 평균값 기준으로 가중 평균.
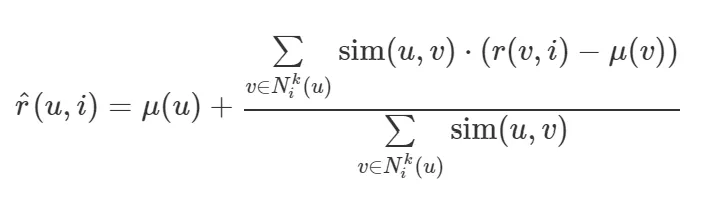
출처 : datascienceschool
(3) KNNBaseline
• 평점들을 베이스라인 모형의 값 기준으로 가중 평균.
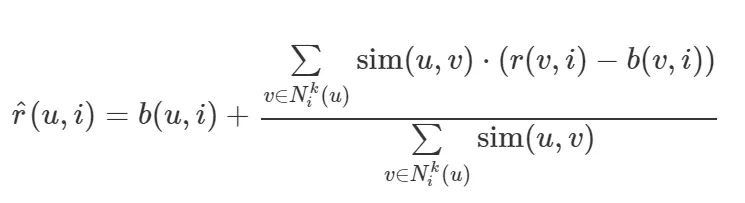
출처 : datascienceschool
3. 코드 구현 및 데모
[코드 구현 및 데모 2]
사용자-영화 평점 데이터를 기반으로 surprise 패키지에서 제공하는 KNNBasic 알고리즘을 사용하여 특정 사용자에 대한 영화 평점을 예측하고자 함. KNNBasic으로 사용자의 유사도를 바탕으로 추천을 생성하며, 여기서는 코사인 유사도를 사용하여 유사한 사용자들의 평점을 반영하여 예측.
1. 모델 선택
•
모델: KNNBasic
2. 유사도 측정 방식
•
유사도 측정 방식: 코사인 유사도 (cosine similarity)
•
유저 기반: 사용자 간의 유사성을 기반으로 평점을 예측.
import pandas as pd
from surprise import Dataset, Reader
from surprise import KNNBasic
from surprise.model_selection import train_test_split
from surprise import accuracy
# 1. 데이터 설정: 사용자-영화 평점 데이터
data_dict = {
'user_id': [1, 1, 1, 2, 2, 2, 3, 3, 3, 4, 4, 4],
'item_id': ['A', 'B', 'C', 'A', 'B', 'D', 'A', 'C', 'D', 'B', 'C', 'D'],
'rating': [5, 4, 3, 4, 5, 2, 5, 4, 3, 2, 3, 5]
}
df = pd.DataFrame(data_dict)
# 2. Surprise 데이터셋 준비
reader = Reader(rating_scale=(1, 5))
data = Dataset.load_from_df(df[['user_id', 'item_id', 'rating']], reader)
# 3. 학습 및 테스트 데이터 분할
trainset, testset = train_test_split(data, test_size=0.2)
# 4. KNNBasic 모델 생성 및 훈련
knn = KNNBasic(sim_options={'name': 'cosine', 'user_based': True}) # 유저 기반 KNN
knn.fit(trainset)
#사용자 간의 유사성을 기반으로 평가를 수행하기 때문에,
#사용자들이 비슷한 취향을 가진 경우 높은 예측 정확도를 제공
# 5. 예측: 사용자 1이 영화 'C'를 평가할 확률 예측
uid = 1 # 사용자 ID
iid = 'C' # 영화 ID
predicted_rating = knn.predict(uid, iid).est
print(f"사용자 {uid}가 영화 '{iid}'에 대한 예측 평점: {predicted_rating:.2f}")
# 6. 모델 평가: RMSE (Root Mean Squared Error)
predictions = knn.test(testset)
rmse = accuracy.rmse(predictions)
print(f"모델 RMSE: {rmse:.2f}")
Python
복사
Computing the cosine similarity matrix...
Done computing similarity matrix.
사용자 1가 영화 'C'에 대한 예측 평점: 3.50
RMSE: 0.9644
모델 RMSE: 0.96
Plain Text
복사
3. 예측 결과
사용자 1이 영화 'C'에 대해 예측한 평점은 3.67로 나타남. 이는 사용자가 'C'에 대해 긍정적인 평가를 할 가능성이 있음을 나타냄.
4. 모델 평가
모델을 학습시키고 테스트 데이터셋에 대해 예측을 수행한 결과, RMSE(Root Mean Squared Error)는 약 0.96로 나타남. 예측 평점과 실제 평점 간의 평균 차이를 나타내며, 값이 낮을수록 모델의 성능이 우수함을 의미. (최대 RMSE : 4)
5. 결론
코사인 유사도를 사용한 KNN 기반 추천 시스템은 사용자 간의 유사성을 효과적으로 평가할 수 있는 방법을 제공하며, 영화 추천 시 사용자 개인의 취향을 잘 반영할 수 있음
참고 자료
•
데이터 사이언스 스쿨
•
wikipedia
