


•
시 계열 스토리지의 사용 상황
◦
상용시스템 성능 지표 수집
데이터가 오래될수록 덜 상세해지도록 조작
◦
로컬 컴퓨터에 복사본 저장
통합하여 압축 보관
◦
여러 다양한 데이터를 통합하여 하나의 시계열 데이터로 통합
원본 데이터들을 건드리지 않고 데이터를 호출하여 가공
•
시스템의 주요 요구 사항에 따른 방법 변화
◦
크기에 따른 성능 확장 방법
오래된 데이터를 삭제하는 자동화된 스크립트를 사용
거대한 데이터의 집합(두 번째 사용 사례) 또는 증가하는 데이터 집합(세 번째 사용 사례)
◦
데이터 접근에 대한 무작위적인 방식 대 순차적 방식
두 번째 사용 사례에서는 모든 데이터가 같은 정도로 접근된다는 것을 기대ㅘ
첫 번째와 세 번째 사용 사례는 가장 최근의 데이터일수록 더 빈번히 접근
◦
자동화 스크립트
첫 번째 사용 사례는 자동화가 필요한 상황, 두 번째 사용 사례는 자동화 불 필요.
세 번째 사용 사례는 약간의 자동화가 필요
5.1 요구 사항 정의
•
얼마나 많은 시계열 데이터를 저장해야 하나요? 얼마나 데이터가 빠르게 증가하나요?
•
측정에 대한 업데이트가 끊임없이 발생하거나(예: 계속 이어지는 웹 트래픽 스트림), 측정이
구분되는 개별 사건 단위로 발생하나요(예: 지난 10년 동안 미국의 모든 주요 공휴일에 대한 시간 별 항공 교통 시계열)
•
데이터가 끊임없이 발생한다면 가장 최근의 데이터를 관찰
•
측정이 구분되는 개별 사건 단위라면 데이터에 대한 무작위적인 접근
•
데이터의 간격이 일정하거나 일정하지 않나요?
◦
데이터의 간격이 일정치 않다면
데이터 접근이 발생하는 시점의 예측이 어렵기 때문에 데이터를 쓰기나 쓰지 않는 기간을 효율적으로 활용 가능 하게 끔 준비
•
지속적으로 데이터를 수집할 것인가요? 아니면 프로젝트가 마무리되는 시점이 정해져 있나요?
◦
데이터 수집이 종료되는 시점이 정해져 있다면
수용해야 할 데이터셋의 크기를 보다 쉽게 예상
•
시계열로 하려는 것이 무엇인가요? 실시간으로 시각화가 필요한가요? 신경망이 수천 번 반복적
으로 접근할 전처리된 데이터가 필요한가요?
•
데이터를 원본 그대로 저장할지, 처리된 형태로 저장할 지, 메모리상의 데이터를 시간축에 따라 위치시킬지, 다른 축에 따라 위치시킬지, 데이터의 읽 고 쓰기에 쉬운 형식으로 저장해야 할지와 같은 사실을 결정
5.1.1 실시간 데이터와 저장된 데이터
불 필요한 데이터의 저장을 피하고, 최적의 스토리지를 구성하여 데이터 찾는 데 드는 시간을 줄여야 함
•
웹페이지를 로딩하는 데 걸리는 시간을 기록하는 웹 서버 를 구동

•
근무시간 동안 성능 문제가 발생하지 않았다는 것을 확인

⇒ 개별 데이터를 모두 저장 하기 보다는 종합하는 기법을 사용하여 데이터 스토리지를 간소화하는 것이 좋음
•
정보의 유실 없이 데이터를 줄일 수 있는 경우
◦
천천히 변하는 변수 ⇒ 값이 변한 데이터만 기록
◦
노이즈가 낀 높은 빈도의 데이터 ⇒ 높은 수준의 노이즈는 각 개별 측정의 가치를 떨어뜨리기 때문에 사전에 데이터의 종합 집계를 고려하여 집계하지 않을 수 있음
◦
오래된 데이터 ⇒ 새로운 시계 열 데이터셋의 기록을 시작할 때마다 시계열 데이터가 언제 도태될지 미리 생각
•
법적 고려 사항을 시스템의 설계에 반영
5.2 데이터베이스 솔루션
•
데이터베이스
◦
데이터 분석가와 엔지니어에게 친숙하고 직관적인 데이터 저장방식을 제공하는 솔루션
•
데이터베이스 선택 이유
◦
여러 서버로 확장 가능한 스토리지
◦
저지연의 읽기/쓰기
◦
일반적인 지표의 내장된 계산 함수
(예: 시간지표에 group-by 연산이 적용 가능할 때 group-by 질의에서 평균을 계산하는 것)
◦
시스템의 성능 튜닝 및 병목 문제 분석에 사용되는 문제 진단 및 모니터링 도구
5.2.1 SQL과 NoSQL
•
SQL
◦
관계형 테이블, 대용량 시계열 데이터 위해 SQL 솔루션 확장시 성능 저하 발생
•
NoSQL
◦
시간 범위가 무한한 시계열 데이터의 수용이 가능하도록 확장될 수 있는 개병형 솔루션 필요시
•
원래의 SQL 데이터베이스로부터 영향을 받은 데이터의 특성
◦
과거 SQL 솔루션은 트랜잭션 데이터 기반
▪
여러 기본키의 속성들로 구성(상품,참가자,시간,거래 가치 같은 정보)
▪
시간도 기본키로 다뤄질 수 있음-권한있는 정보축이 되어선 안됨
◦
시계열과는 다른 트랜잭션 데이터의 주요 특징
▪
이미 존재하는 데이터의 업데이트 빈번히 발생
▪
기본적으로 데이터가 정렬되지 않아 무작위적인 접근 이뤄짐
•
시계열 데이터의 특성
◦
이력(history)을 상세히 다룸(트랜잭션 형태의 기록은 최종 상태만 알 수 있음)
◦
업데이트되지 않는 것이 일반적
◦
데이터를 임의의 순서로 쓸 수 있는 작업은 중요치 않음
◦
읽기 작업보다 쓰기 작업이 빈번하게 발생함
◦
데이터의 쓰기, 읽기 업데이트 작업은 일련의 사건이 일어나는 시간 순서에 따라 이루어짐
◦
트랜잭션 데이터보다 훨씬 더 동시성 읽기가 수행될 가능성이 높음
◦
시간 외에 변수를 기본키로 두는 경우는 매우 드묾
◦
개별 데이터 삭제보다 데이터 뭉치를 삭제하는 것이 더 일반적
→ NoSQL 데이터베이스가 시계열 데이터에 좀 더 적합
→ NoSQL이 SQL보다 쓰기작업 성능 뛰어남
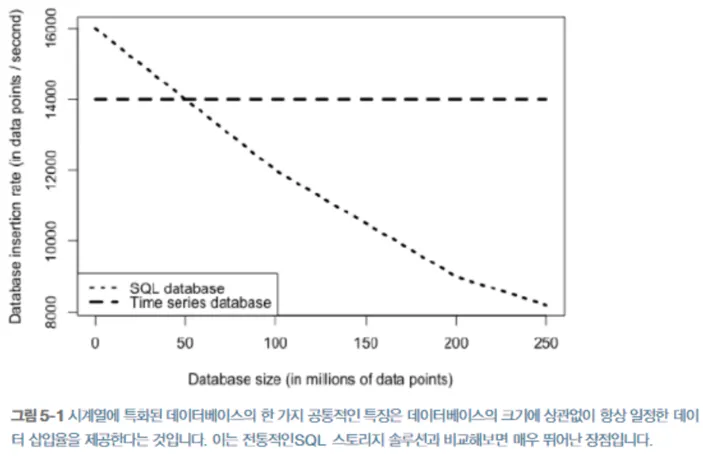
•
SQL과 NoSQL을 선택하는 방법
◦
데이터를 고려할 때 어떤 스토리지에도 항상 적용되는 원칙
→ 같은 시간에 요청되는 경향이 있는 데이터는 같은 위치에 저장되어야 함
•
시계열에 대해 SQL의 장점
◦
해당 데이터베이스에 이미 저장된 관련성을 가진 다른 비시계열 데이터와 손쉽게 연관 가능
◦
계층적인 시계열 데이터-관계형 테이블 적절함, 계층 설명과 관련 시계열의 그룹화 가능
◦
SQL 데이터베이스에 가장 잘 맞는 트랜잭션 데이터 기반한 시계열
→ 시계열의 동일 데이터베이스에 저장하여 쉬운 검증 및 상호 참조 등의 이점
•
시계열에 대해 NoSQL의 장점
◦
스키마가 없거나 유연한 스키마
◦
비구조화된 데이터
◦
대용량 및 분산 데이터 처리 적합
◦
쓰기 속도가 빠름
◦
비전문가도 즉시 사용이 가능함
5.2.2 인기 있는 시계열 데이터베이스와 파일 솔루션
•
시계열에 특화된 데이터베이스
◦
인플럭스 DB
▪
오픈소스 시계열 데이터 베이스, 평가 지표, 사건의 기록과 성능 분석에 유용
▪
푸시기반 데이터베이스 시스템(직접 데이터를 넣어줘야 함)
▪
시간 인식-모든 데이터 타임스탬프 자동적용
▪
SQL과 유사한 질의 방식 사용 (SELECT * FROM access_counts WHERE value >10000)
▪
구성 요소
•
타임스템프
•
측정 내용을 나타내는 레이블
•
하나 이상의 키/값 필드(예:온도=25.3)
•
키/값의 쌍으로 구성된 메타데이터 태그 정보
▪
장점
•
오래된 데이터의 지정 및 삭제 작업을 쉽게 자동화할 수 있는 데이터 보존 기능
•
데이터의 빠른 수집 속도 및 적극적인 데이터 압축 기능
•
시계열이 특정 기준으로 빠르게 색인하기 위해 각 시계열에 태그를 달 수 있는 기능
•
시계열 데이터의 수집, 저장, 모니터링, 출력 모두를 포함하는 성숙된 TICK 스택의 한부분을 차지하여 해당 스택과 쉬운 조화가 가능
•
시계열 스토리지 솔루션을 배가할 수 있는 성능 모니터링 도구
◦
프로메테우스
▪
HTTP 기반으로 동작하는 모니터링 시스템 & 시계열 데이터베이스
▪
풀기반pull-based 시스템
•
장점
◦
시계열 데이터 수집 방법 및 중앙 서버에 저장되는 데이터의 빈도에 대해 로직을 쉽게 조정하고 검사할 수 있음
◦
성능 모니터링을 위한 빠르고 간편 기술
•
단점
◦
데이터가 완전 최신 상태라고 장담할 수 없음
◦
데이터가 항상 100% 정확해야 하는 애플리케이션에 적합하지 않음
▪
질의에 PromQL라는 함수표현 언어사용
▪
PromQL을 통해 시계열에서 다뤄지는 여러 일반적인 작업을 위한 API 제공
•
Predict_linear() 예측 수행
•
Rate() 시계열의 단위 시간당 증가율 계산, 간단한 인터페이스 통해 일정기간 집계 가능
▪
유지보수를 위한 모니터링과 분석에 집중하는 경향 보임(데이터 관리 위한 자동화 기능 부족)
▪
실시간 스트리밍 애플리케이션, 데이터 가용성이 가장 중요한 상황에 유용한 시계열 스토리지 솔루션임
•
범용 NoSQL 데이터 베이스
◦
테이블 구조가 아닌 문서 구조에 기반
◦
시계열에 특화된 기능을 많이 포함하지 않는 것이 일반적
◦
유연한 스키마 덕분에 시계열 데이터에 유용
▪
데이터수집,채널 개수 변동 있는 새로운 프로젝트에서 유용
▪
SQL 시간에 따란 변화하는 구조에서 NaN 발생, 직사각형 형태로 데이터 유지
▪
NoSQL 누락된 데이터의 특정값은 단순히 누락된 상태 그대로
◦
몽고DB(스키마의 유연성)
▪
성능좋은 NoSQL 기반 시계열 데이터베이스
▪
IoT 친화적인 구조 및 지침의 개발
▪
시간 및 시간 관련 그룹 단위의 고수위 집계 기능을 제공
▪
요일 또는 월처럼 사람이 이해하기 편한 형식으로 시간을 나누는 자동화기능 제공
•
$day0fWeek
•
$day0Month
•
$hour
▪
광범위한 문서화 작업
5.3 파일 솔루션
•
데이터베이스
◦
스크립트+데이터 스토리지 모두 통합하여 작업 수행하는 소프트웨어à 단층 파일이 됨
•
단층파일 선택하는 경우
◦
성숙된 데이터 형식 완성되어 오랜 기간동안 합리적으로 그 명세를 따를 수 있는 경우
◦
데이터 처리가 I/O와 밀접하게 관련, 속도의 향상에 개발 시간을 할애하는 것이 합리적인 경우
◦
데이터의 무작위적인 접근보다 순차적 접근이 필요한 경우
•
데이터베이스로의 데이터를 단층파일로 마이그레이션할 만한 이점
◦
단층파일은 특정 시스템에 종속적이지 않음
▪
데이터 공유시 파일을 이미 알려진 형식으로 제공
▪
데이터 원격접근, 미러링된 데이터 베이스 구축 요청 필요없음
◦
단층파일이 데이터베이스보다 I/O 오버헤드 낮음
▪
단층파일을 읽는 작업이 훨씬 간결
◦
단층파일에서는 데이터의 읽히는 순서 표현가능
◦
데이터를 가능한 최대로 압축가능 훨씬 적은 양의 메모리 차지
5.3.1 넘파이 & 5.3.2 팬더스
•
넘파이
◦
데이터 순수 수치형으로만 구성시, 수치형 데이터 보관에 널리 사용되는 방식(파이썬 넘파이)
◦
이점
▪
여러가지 저장 옵션 제공
▪
형식의 성능을 상대적으로 비교하는 많은 벤치마크 자료가 공개되어 있음
▪
스토리지나 분석 측면에서 볼때 즉시 사용 가능한 좋은 성능 수준 만족하는 데이터구조
◦
단점
▪
단일 데이터 형식만 존재
▪
행과 열에 레이블을 추가하는 자연스러운 방법 없음
•
팬더스
◦
손쉬운 데이터의 레이블링
◦
서로다른 시계열 데이터의 저장
◦
여러종류의 데이터로 구성된 시계열 데이터에서 유용
▪
발생한 사건수(int), 상태의 측정(flat), 레이블(string 또는 원핫 인코딩)등 여러 종류의 데이터로 구성
5.3.3 표준 R에 동등한 것 & 5.3.4 Xarray
•
장점
◦
R 객체는 기본적으로 .Rds와 .Rdata 형식으로 저장
◦
이진 파일 형식
◦
텍스트 기반 형식보다 압축과 I/O 측면에서 효율적
◦
언어에 비종속적인 형식으로 데이터 저장
•
단점
◦
이진형식 대신 텍스트 기반의 파일형식 사용시 저장 공간의 상승과 I/O 속도저하 발생

파일 형식 옵션에 따른 크기 및 성능 비교
•
Xarray
◦
시계열 데이터가 다차원적으로 넓어지면 Xarry가 유용함
◦
Xarray가 유용한 이유
▪
차원에 명명할 수 있는 기능 제공
▪
넘파이 같이 벡터화된 수학적 연산 제공
▪
팬더스같이 그룹화 연산의 제공
▪
데이터베이스같이 시간 범위 기반의 색인 기능 제공
▪
다양한 파일 스토리지의 옵션 제공(pickle 및 netCDF 이진파일 형식두개 지원)
◦
시간에 대한 색인 및 리샘플링
◦
특정 시간의 개별 요소에 대한 접근
→ 시간에 특화된 다양한 연산을 지원하는 데이터 구조
