

.png&blockId=04a8d577-ace8-4bac-bec8-3da8a3f63bbd)

@7/27/2022
Local Interpretable Model-agnostic Explanation (Ribeiro 2016)
지역적으로 근사하는 대리 모델(surrogate model)을 생성하여 복잡한 모델을 설명하는 기법
1. Overview
특징
•
Model-agnostic: 모델 유형에 상관 없이 적용 가능한 기법
•
복잡도가 높은 원본 모델로부터 지역적으로 근사하는 단순한 대리 모델을 생성하여 설명
◦
Linear regression 모델의 경우, 회귀계수를 통해 설명함. 또한, Decision tree 의 경우 노드의 분류 규칙을 통해 설명
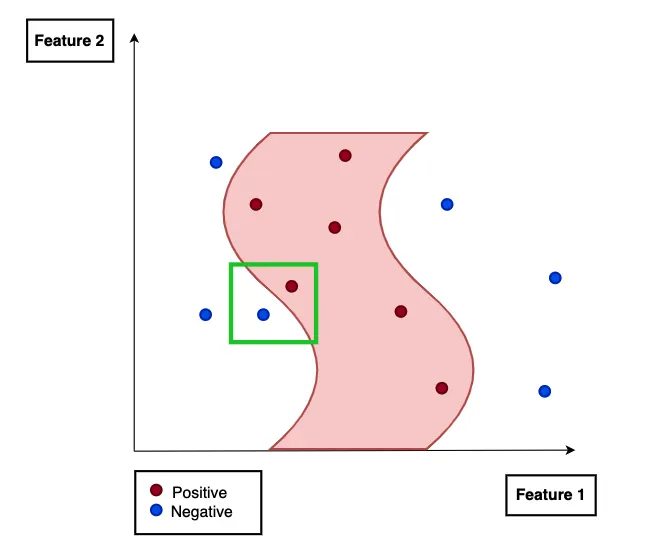
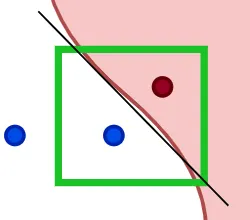
(위) 모델의 복잡한 결정 경계 (아래) 특정 인스턴스를 중심으로 확대한 화면. 복잡한 결정 경계를 선형으로 근사하는 대리 모델의 결정 경계를 확인할 수 있다. (출처: Mattias Lee)
•
다양한 데이터 유형에 적용 가능하며, 별도의 시각화 결과를 제공

LIME 설명 예: 이미지 분류

LIME 설명 예: 자연어 처리(재난 관련 텍스트 분류)

LIME 설명 예: Tabular 데이터(와인 품질 예측)
LIME 기법의 유형
개별 인스턴스를 중심으로 설명하기 위한 기본 LIME 알고리즘과 다수의 인스턴스들을 설명함으로써 모델의 신뢰성을 평가하기 위한 SP-LIME(Submodular Pick for LIME) 알고리즘으로 구성됨
2. Main Concepts
2. 1 Fidelity-Interpretability Trade-off
: Locality-aware loss 로서 원본 모델의 예측과 생성한 설명 모델의 예측 사이의 오차를 통해 설명 모델이 원본 모델에 근사하는 정도를 평가
•
: 원본 모델
•
: LIME 에 의해 생성된 설명 가능한 모델들의 집합
◦
예: 선형 모델(Linear / Logistics regression), Decision trees, Falling rule lists
◦
: 를 근사하는 설명 모델
•
: 설명하고자 하는 특정 인스턴스
•
: 근처에 임의로 생성한 인스턴스(perturbed)
◦
: 생성된 인스턴스 가 설명 모델 에 맞게 차원이 축소된 버전
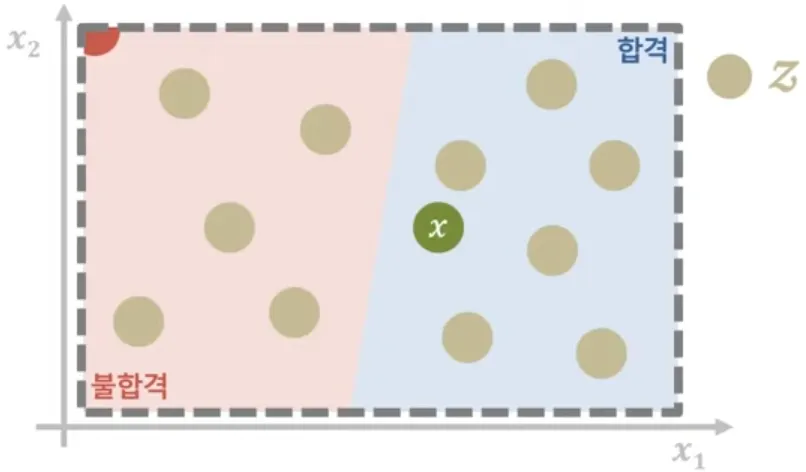
설명하고자 하는 인스턴스 x와 이를 위해 생성한 인스턴스 z (출처: DMQA)
•
: 설명 대상인 인스턴스 와 생성한 인스턴스 사이의 거리 함수. 출력 값은 에 대한 가중치로 사용됨
Locality-aware loss 는 다음과 같은 수식을 따름
해설: 설명 대상인 인스턴스 에 대하여, 단순하지만 좋은 설명 모델 를 찾기 위해 특징 값을 조금씩 바꾸면서(perturbation), 근처에 여러 개의 인스턴스 를 생성한다. 각 는 모두 똑같은 취급을 받지 않고, 거리함수 에 의해 에 근접할수록 높은 가중치를 부여 받는다. 이 값은 오차항과 곱해지는 데, 오차는 에 대하여 원본 모델 가 예측한 값 와 설명 모델 가 차원 축소된 에 대하여 예측한 값 사이의 오차 제곱으로 계산된다.
: 모델의 복잡도(complexity)
•
예(Decision Tree): 트리의 깊이
•
예(Linear models): 가중치(회귀 계수)의 수()
결론적으로 전체 수식에 의해 LIME 알고리즘은 원본 모델에 최대한 근사하면서도 복잡도가 낮은 설명 모델을 탐색하는 방향으로 동작
2.2 Sparse Linear Explanation
거리함수 에 대한 설계 내용(exponential kernel)과 수식
2.3 Submodular Pick for Explaining Models
기본 LIME 이 단일 인스턴스에 대한 설명을 제공하는 한계점을 보완하여, 데이터셋을 대표하는 다수의 인스턴스들을 중심으로 설명 모델들을 생성하여, 원본 모델의 신뢰성을 평가하는 기법
→ 기본 LIME 알고리즘의 반복문으로 비유할 수 있음
2.4 Feature Importance
회귀 문제의 경우, LIME Python 패키지는 기본적으로 Ridge regression을 통해 설명 모델을 생성하며, 최종적으로 설명 모델의 회귀계수(non-zero coefficients)를 통해 인스턴스 또는 모델을 설명함
References
1.
2.
3.
Understanding how LIME explains predictions, Towards Data Science
a.
LIME의 주요 과정과 자세한 수식 설명
4.
(Ribeiro 2016) "Why should i trust you?": Explaining the predictions of any classifier, ACM SIGKDD
a.
Seed Paper
