


논문 개요
•
제목: A feature selection method based on feature importance for retail sales forecasting
•
제목(국문): 판매 예측을 위한 특징 중요도 기반 특징 선택 방법
◦
특징 중요도
•
APIC-IST 2022 논문 기반하여 작성
•
컨텐츠: 그림 3, 표 7, 수식 7+, 알고리즘 1, 코드 2
•
논문 파일
TDL
Related Works
특징 공학
•
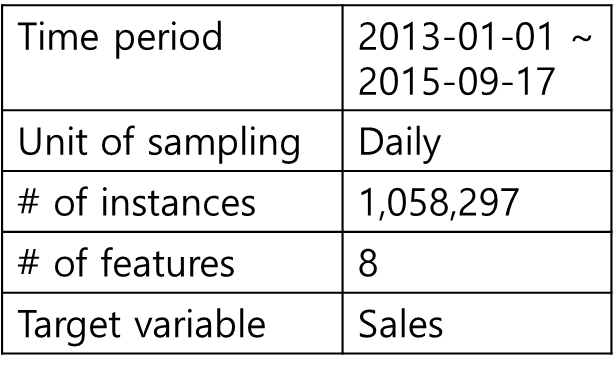
데이터셋: Rossmann store sales dataset
◦
[표] 데이터셋 요약 → 텍스트로 대체
◦
# stores: 1115
◦
[표] 데이터 속성
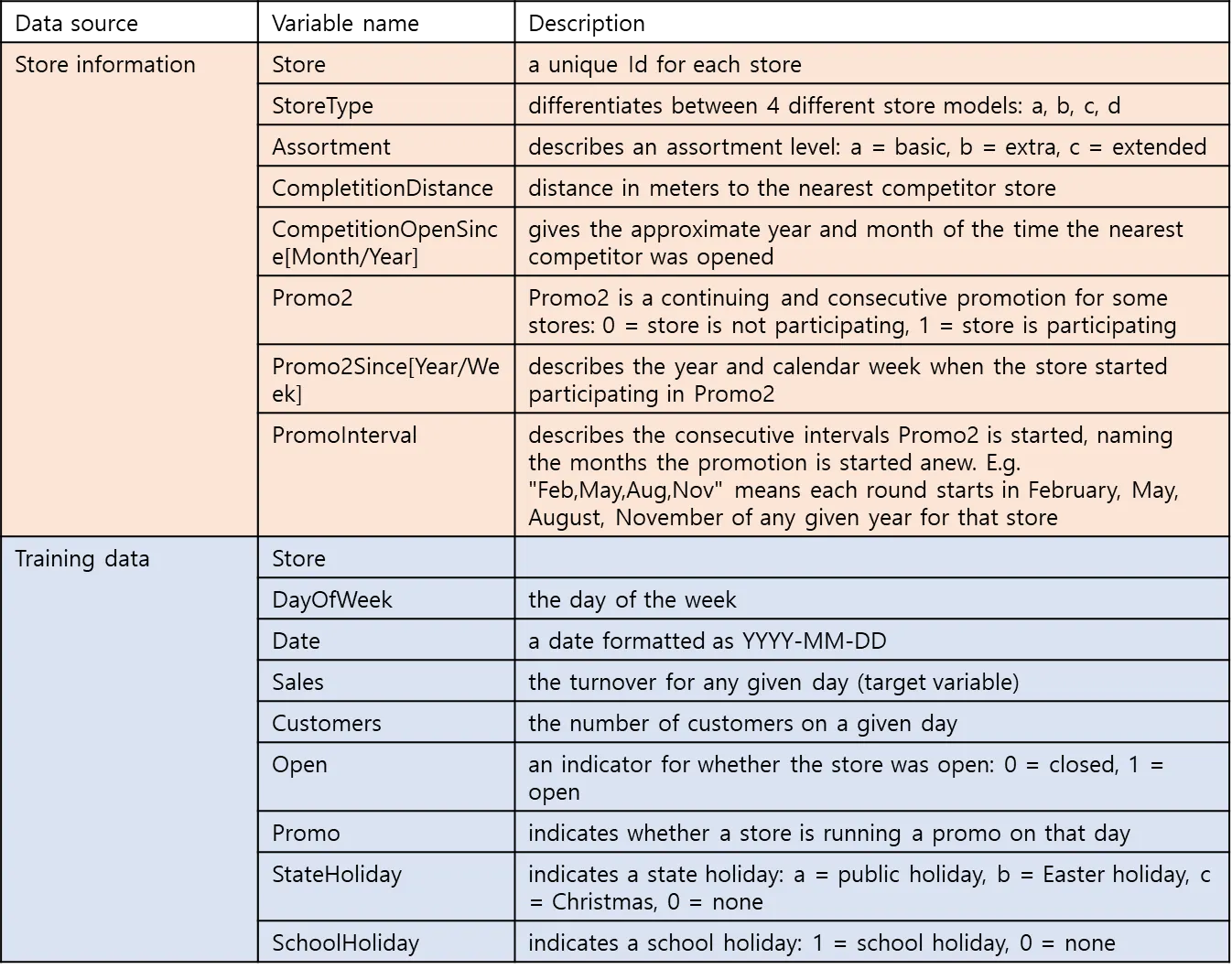

[Weng] 특징 설명
•
Data Cleaning
◦
유효하지 않은 데이터 처리(Correction of invalid data):
▪
[코드] ‘StateHoliday’ 정수 0(undefined)을 문자 ‘0’ 으로 변환
train.StateHoliday.replace(0, '0', inplace=True)
Python
복사
▪
비영업일(Open = 0) 데이터 제거
◦
[코드] 결측치 처리(Fill missing data)
store['CompetitionDistance'].fillna(store['CompetitionDistance'].median(), inplace=True)
store.fillna(0, inplace=True)
Python
복사
◦
이상치 제거 및 평탄화: IQR
▪
[수식] IQR
▪
[수식] Mild and Extreme Outliers
◦
특징 정규화: min-max normalization
▪
[수식] min-max normalization
•
Feature Engineering
◦
특징 설계 및 추출: CompetitionOpenElapsedDays, Promo2ElapsedDays
▪
[코드] 특징 추출 코드
◦
특징 인코딩: 모두 nominal 변수이므로 원핫인코딩 적용
•
EDA
◦
[표] Store Sales, # Customers 기술 통계
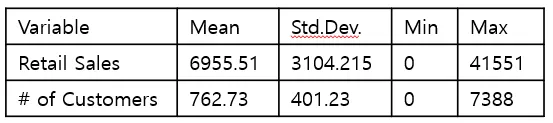
Summary of the descriptive statistics of the sales and number of customers
◦
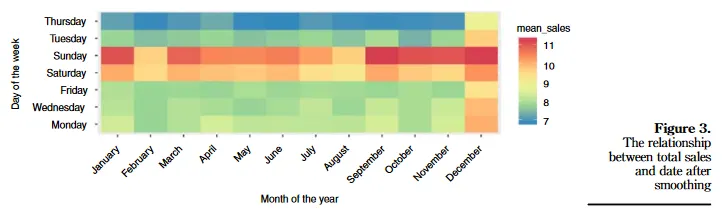
[그림] 주요 지표 시계열: (a) Sales (b) # Customers


◦
[그림] Promo2 에 따른 분포 비교: (a) Store Sales Distribution (b) Customers Distribution


Distributions of (a) sales and (b) no. of customers
[Weng]
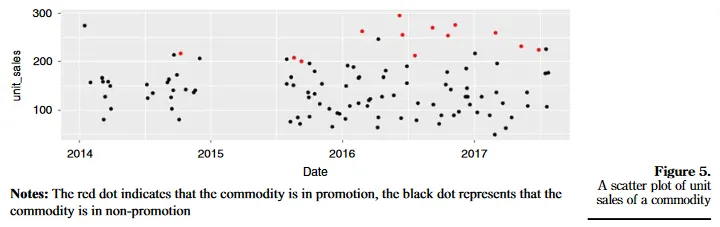
[Weng] 프로모션 참가/미참가 지점 별 매출 비교
◦
[그림] Correlation (수치형), (범주형)
▪
•
Feature Importance
◦
Impurity-based
▪
[수식+] Impurity-based 특징 중요도
“The higher, the more important the feature. The importance of a feature is computed as the (normalized) total reduction of the criterion brought by that feature. It is also known as the Gini importance.” - sklearn.ensemble.RandomForestRegressor
The function to measure the quality of a split. Supported criteria are “squared_error” for the mean squared error, which is equal to variance reduction as feature selection criterion, “absolute_error” for the mean absolute error, and “poisson” which uses reduction in Poisson deviance to find splits. Training using “absolute_error” is significantly slower than when using “squared_error”. sklearn.ensemble.RandomForestRegressor
“Feature importance is calculated as the decrease in node impurity weighted by the probability of reaching that node. The node probability can be calculated by the number of samples that reach the node, divided by the total number of samples. The higher the value the more important the feature.” - The Mathematics of Decision Trees, Random Forest and Feature Importance in Scikit-learn and Spark
▪
•
Regression tree 에서의 Impurity 계산
◦
LIME
▪
[수식 +] LIME 특징 중요도
•
Feature Selection
◦
[수식] 특징 랭킹
◦
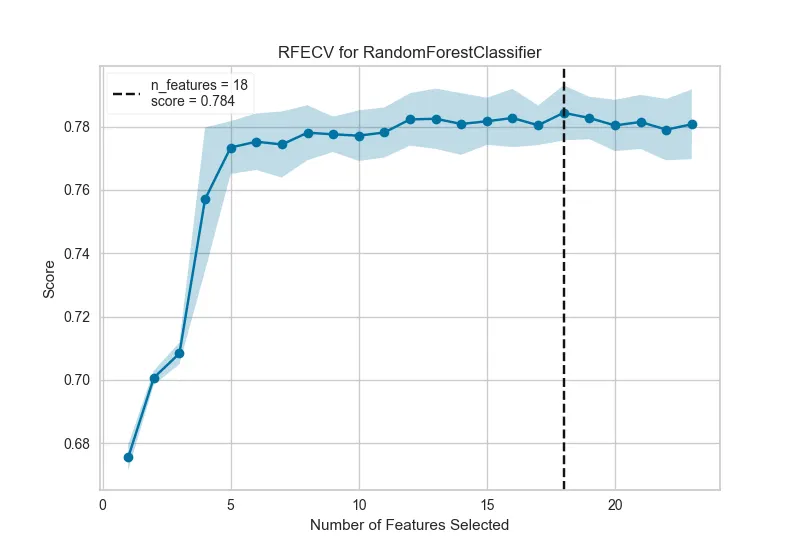
RFE (Recursive Feature Elimination): 특징 수 n 을 정하면 모든 특징에서 n 까지 차례대로 제거하는 방식 → 본 논문에서는 성능 감소 임계치를 이용하여 RFE 를 수행
◦
[알고리즘] RFE
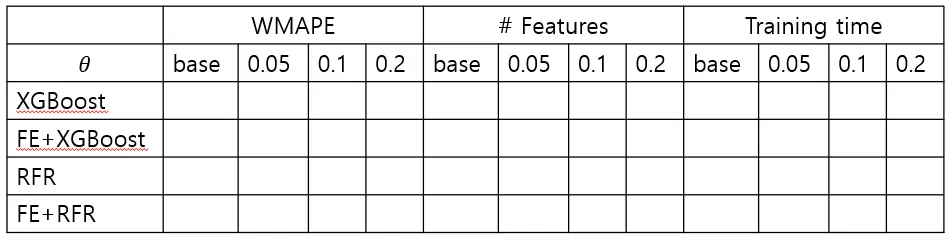
실험 설계
•
모델: Ensemble Methods
1.
Random Forest Regressor (Bagging 계열)
2.
LightGBM(Boosting 계열)
•
[표] Experimental Settings
•
[표] RFR 모델 매개변수
•
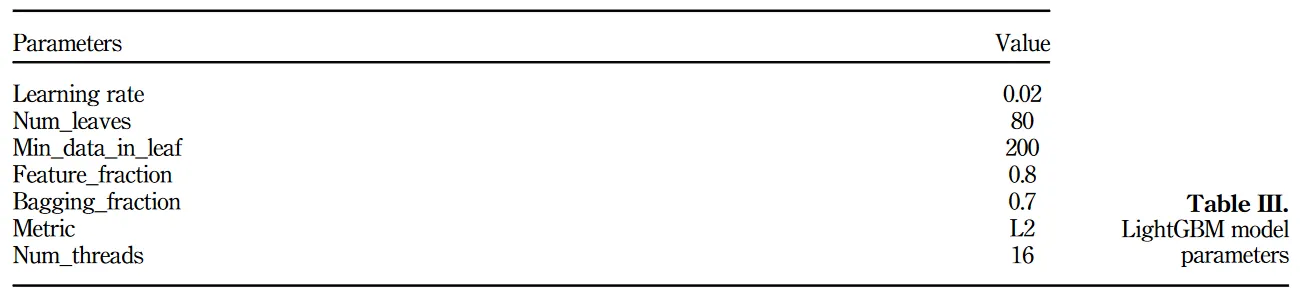
[표] LightGBM 모델 매개변수
◦
예: LightGBM
•
[표] 특징 중요도 측정 및 랭킹 결과
•
평가지표
◦
[수식] 손실 함수: WMAPE (CMC 논문 참고)
◦
계산 비용: Training time
•
•
[표] 실험 결과 요약
참고문헌
•
◦
RFR 매개변수 설명 및 성능 실험 결과
